
Old Portal Decommissioning
The old portal has now been decommissioned
- The old portal is no longer publicly accessible. You can contact our support department if you still need to access the unmaintained old portal (at your own risk).
- All visitors to
portal.clarifai.com will be hard redirected to clarifai.com/explore.
- If you have any questions, you can always reach our support team at support@clarifai.com
Have you tried new portal yet? We’ve totally rebuilt it to offer the following capabilities:
- A faster user experience: A sleek, modern design and an advanced tech stack that is easier to use and more technical documentation.
- Improved dataset management with enhanced dataset organization, versioning capability, and dataset exporting. Dataset annotations can be specific to each version of a dataset.
- New Team & Organization management functionality: Fine-grained access control of all your AI resources, at an individual collaborator or team level, within or outside your organization.
- Powerful input management: Experience the improved Input Uploader, a more powerful Input Manager with dataset input assignment, multimodal concept search, and a unified UI for viewing your prediction & annotation results.
- Advanced model training: Transfer learning to quickly fine-tune models, and deep training to fully train models with new optimized templates with just a few clicks.
- New Model evaluation modules: We’ve built powerful evaluation modules for image classification, image detection, and text classification.
- Application markdowns: Add a cover image and create detailed markdown documents explaining your application before publishing it to your colleagues or the public.
- Bulk label faster than ever: Using complex text descriptions and our multi-modal search, label hundreds of images with a single click from the input manager.
- Label images faster: Whether it’s annotations, bounding boxes, or segmentation, you can now label right from inside the viewer.
- Model version management: Track the different versions of your models as you improve them.
- Community: Use hundreds of open-source and community models from Clarifai and our users in your apps. Star and pin your favorites, and share your work with the Clarifai Community.
Clarifai Community
Introduced modules as a way to extend Clarifai’s UIs and perform customized backend processing
- Modules are custom plugins that provide both UI elements and the ability to perform some computation around our API.
- You can now use modules to extend Clarifai UIs, augment backend processing capabilities, and build customized solutions quickly and easily.
Generative Models
Added more model options to allow our users to unleash the power of the latest developments in Generative AI
We are continuing to wrap more generative models and LLMs from various vendors into our platform. We intend to provide you with more generative options so that you can choose the best one for the task at hand.
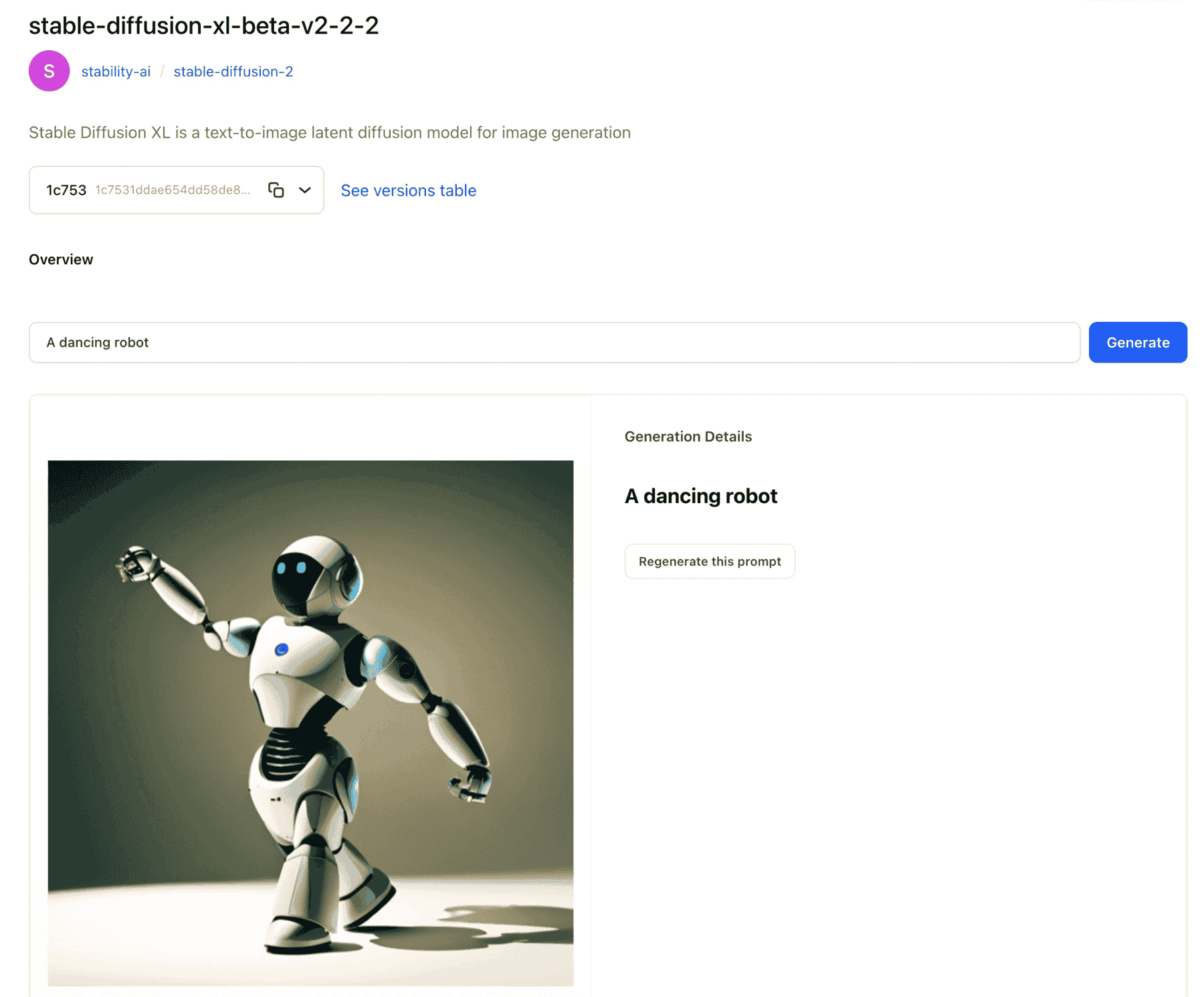
- We've wrapped the following model from Stability AI:
Stable-Diffusion-XL-beta-v2-2-2 for text-to-image tasks.
- We've wrapped the following model from Anthropic:
claude-v1 for text-to-text tasks.
Performed LLM fine-tuning on mid-large size models
- We performed LLM fine-tuning with various base models from
gpt-neo to roberta-xlm-lage using Parameter-Efficient Fine-Tuning (PEFT). We used the LoRA (low-rank adaptation) technique to freeze the weights of the pre-trained models and fine-tune them with a small model, achieving excellent fine-tuning results. The supported "fine-tunable" tasks include text classification (9.6 released) and text generation, such as content creation (coming soon in 9.7 release).
- You can now perform text classification with two new templates:
gpt-neo-125m-lora and gpt-neo-2.7b-lora.
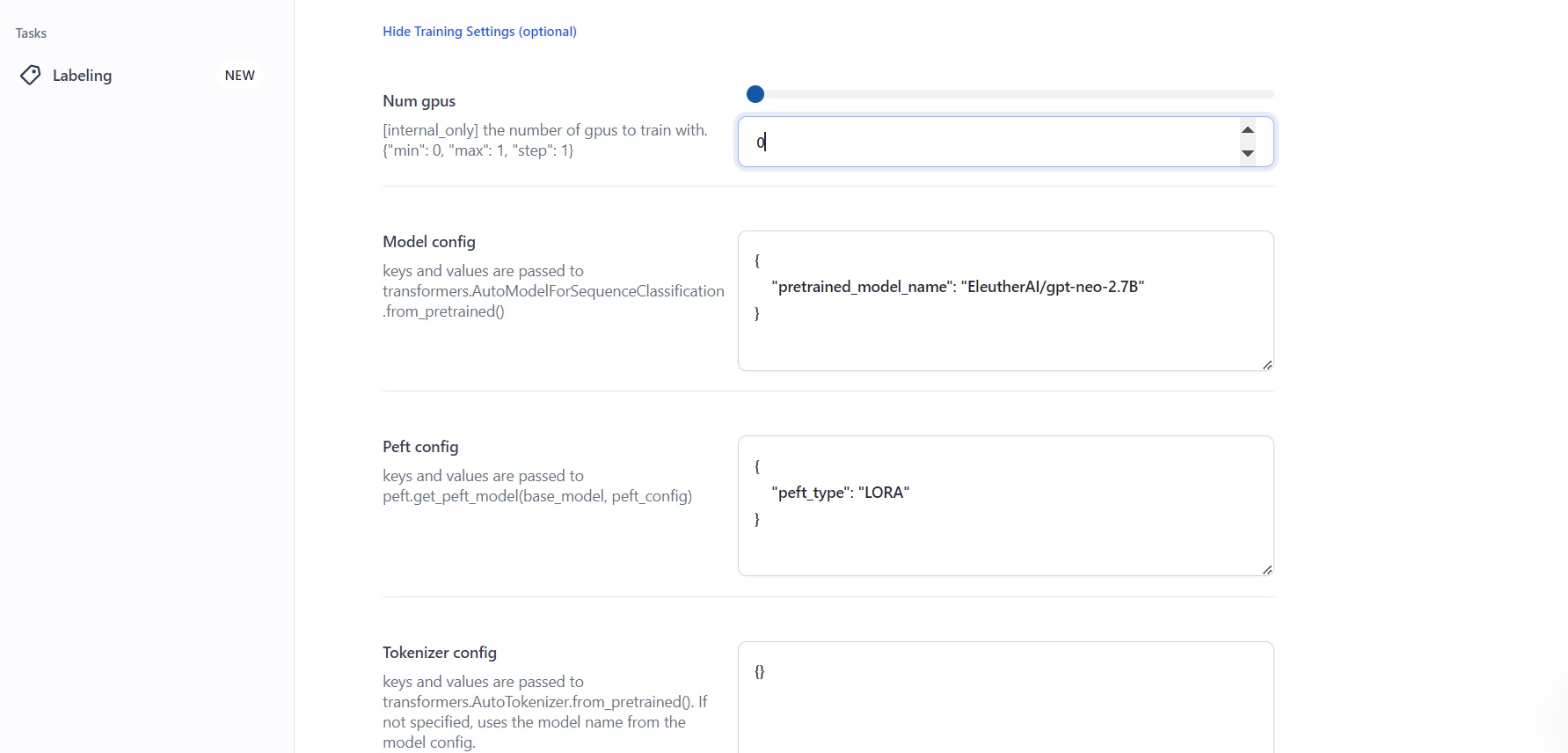
- We also added the ability for users to perform advanced custom model configurations. For example, you can set up PEFT, which allows you to get performance comparable to full fine-tuning while only having a small number of trainable parameters.
- To use PEFT, create a text classifier, set the template type to use LORA, and access PEFT.
Performed LLM inferencing of mid-large size models
We performed inferencing on the following open source LLMs: hkunlp_instructor-xl and tiiuae-falcon-7b-instruct. We exposed the trained models to novel data and got predictions (inferences), which allowed us to optimize their performance.
Input-Manager
Improvements
- We've improved the efficiency and fixed some bugs related to importing large batches of inputs via the input uploader. You'll now get a better experience when importing batches of inputs by uploading files, URLs, or texts. You can also efficiently monitor the status of the inputs during and after the upload exercise.
Bug Fixes
- Fixed an issue that prevented the unification of Input-Manager and Input-Viewer stores. Previously, if you clicked the spyglass icon on an image on the Input-Manager page to perform a visual or face similarity search, and then clicked on any of the images returned by the search, the right image you clicked could not be populated on the Input-Viewer page. The issue has been fixed.
- Fixed an issue that caused slow visual similarity searches. We've improved the speed and efficiency of visual similarity searches.
- Fixed an issue that prevented new datasets from appearing under the Input Filters section on the Input-Manager. If you now use the input uploader pop-up window to add a new dataset, it will be correctly listed under Datasets without any issues.
- Fixed some issues that caused incorrect styling of the upload job monitor window on the Input-Manager.
- If some upload jobs are being processed and you collapse the upload monitor, a blue line is now displayed at the bottom of the upload monitor. It turns to green once the upload is successful.
- If you select some inputs while the upload monitor is still active, the selected items now overlap the upload monitor at the bottom bar.
- There is a blue line that shows a percentage of the status of the upload process.
- Fixed an issue that caused the inputs upload process to fail when one upload job failed. Previously, if you uploaded inputs in bulk, and one input failed to upload properly, the entire upload process failed. We've fixed the issue by showing an error message for the failed upload, while continuing uploading the rest of the inputs.
- Fixed an issue that prevented Smart Search results from being loaded after a user pressed the enter button on a keyboard. We've fixed the issue, and Smart Search now works as expected, and with better efficiency.
Input-Viewer
Added ability to hover in order to reveal helpful tips about the labeling tools on the Input-Viewer
If you now hover over a tool icon, you'll reveal a helpful tooltip, including an illustrative animation, a description, and a hotkey. The enhanced tooltips significantly improve the accessibility and usability of the Input-Viewer.
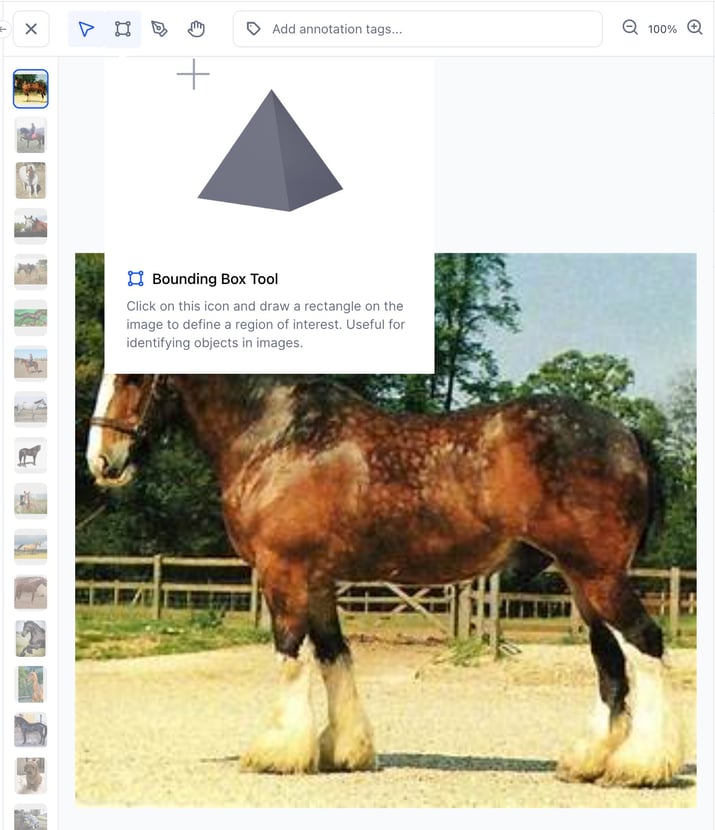
Bug Fixes
- Fixed an issue that prevented filtering of annotations on the Input-Viewer. If you now select the filter option, it's immediately applied and works as expected.
- Fixed an issue with drawing a second bounding box or a polygon on the Input-Viewer. To annotate an input with a bounding box, you go to the Input-Viewer screen, switch to the bounding box mode, select a concept, and draw it on the canvas area.
- Previously, if you wanted to add a second bounding box, the canvas area could become grey without any concept selected.
- You can now add a second bounding box without experiencing any issues.
- Fixed an issue that prevented editing existing polygon annotation points on the Input-Viewer. Previously, if you tried editing an existing polygon point, a new point was created instead of modifying the old one. You can now click on a polygon shape and edit any point without any issues.
- Fixed an issue that caused unexpected backend search requests while scrolling on the Input-Viewer. Previously, there was an issue with the PostInputSearches endpoint that caused improper accumulation of input status filters when performing infinite scrolling. We've fixed the issue.
- Fixed an issue that prevented the rendering of text inputs on the Input-Viewer when Secure Data Hosting (SDH) was enabled. Previously, if you created an app with the base workflow set to "Text" and uploaded a CSV file having text inputs, the uploaded data could not be rendered properly. We've fixed the issue.
- Fixed an issue that prevented the rendering of images on the canvas area on the Input-Viewer when SDH was enabled. Images are now rendering properly on the canvas area when SDH is enabled.
- Fixed an issue that prevented tool icons from showing an active state on the Input-Viewer. Previously, the tool icons did not render an active, or selected, state style, which made it difficult to know the tool you've selected for performing an action, such as drawing a bounding box or a polygon. We've fixed the issue—there is always one tool with an active, or selected, state styling on the Input-Viewer toolbar.
- Fixed an issue that prevented using up/down hotkeys to navigate between inputs on the Input-Viewer. You can now use the up/down hotkeys to successfully navigate between inputs.
- Fixed an issue that caused incorrect responsive styling of sidebar preview items on the Input-Viewer. Vertical scrolling now appears after a user has added a 5th concept. Before the 5th item, vertical scrolling does not appear. If the content fits into the box, the concepts do not have horizontal scrolling.
User Onboarding
Bug Fixes
- Fixed an issue where the onboarding window popped up when a user clicked a non-existent URL. The tasks listing table now displays labeling tasks correctly with no errors.
Models
Published BLIP-2 image captioning and multi-modal embedding models
We've published the general-english-image-caption-blip-2 model.
Improvements
- Introduced the use of the logged-in user's PAT (Personal Access Token) when showing the Call by API code samples. Previously, using an organization's PAT in the Call by API code samples gave an error from the backend. Therefore, we now always fetch the logged-in user’s PAT to be used in the Call by API samples.
- Improved the URL structure of model versions. The URL of a model version now has a
/versions/ reference in its path. It makes the URL fully qualified and easy to infer.
- Improved the animations of the "Try your own image or video" and "Add Public Preview Examples" buttons. If you now hover over either of the buttons on a model overview page, an improved pop-up will appear with a simple animation.
- Added "Try your own inputs" support for transfer learned models. You can now use the "Try your own inputs" feature with transfer learned models. Previously, it wasn’t supported.
- Made some UI/UX improvements on the Model-Viewer page.
- OCR models now support scores output.
- Improved the Model ID and Description fields.
- Moved preview examples to the left side of the Canvas.
Bug Fixes
- Fixed an issue where it was not possible to hover over a smaller bounding box that was within a larger bounding box. Previously, hovering over bounding box predictions of some models was not working very well. Bounding boxes that were inside other bounding boxes could not detect the hovering effect. We've fixed the issue.
Workflows
Bug Fixes
- Fixed an issue that prevented saving workflows. You can now create and save a workflow using the "Save Workflow" button without experiencing any issues.
- Fixed an issue with using the Suppress output field to edit a workflow. Previously, you could check the Suppress output field and update a workflow. However, if you tried editing the workflow again, you could find that the checkbox was incorrectly showing as unchecked. We've fixed the issue.
Apps
Added a toggle to make an app private or public.
You can now use the toggle button on an App Settings page to update its visibility to either private or public.
Email
Bug Fixes
- Fixed an error shown in the verification link of a secondary email. Previously, when a user added a secondary email to their account, and clicked the verification and login link sent to their inbox, they could get an error. We've fixed the issue.




