This blog post focuses on new features and improvements. For a comprehensive list including bug fixes, please see the release notes.
API
Improved the Platform Tracker performance with a detect-track workflow
- Introduced the state-of-the-art BYTE-Track, an online multi-object tracking system built upon the principles of Simple Online and Realtime Tracking (SORT). With BYTE-Track, users can seamlessly integrate it into their detect-track workflows, unlocking advanced capabilities for efficient object tracking.
Python SDK
- You can now configure inference parameters such as temperature, max tokens, and more, depending on the specific model you are using, for both text-to-text and text-to-image generative tasks. This empowers you to customize and fine-tune your model interactions to better suit your individual needs.
Added a robust search interface within the Python SDK for image and text inputs
The SDK now supports vector search (ranking) capabilities and offers advanced filtering options by parameters.
- You can flexibly refine search results using a variety of criteria, including concepts, image bytes, image URLs, text descriptions, embedded metadata tags, and geo points (longitude and latitude, with radius limits).
- The search interface also supports AND and OR operators for complex queries.
- The SDK has also been updated to include schema validation checks to ensure data integrity and search accuracy.
You can get examples of how the search functionality works here.
Integrations
Introduced Clarifai and Databricks integration
This integration is achieved via the Clarifai Python SDK and it is available here.
- This integration enables developers to efficiently manage unstructured data and computing tasks while leveraging Clarifai's computer vision and natural language capabilities.
- It facilitates seamless data ingestion and movement between Databricks and Clarifai.
PAT
Added ability to automatically generate a Personal Access Token (PAT) when you create an account
- Previously, only app-specific keys were automatically generated when you created an app. A PAT will also now be generated for you during account creation.
New Published Models
Published several new, ground-breaking models
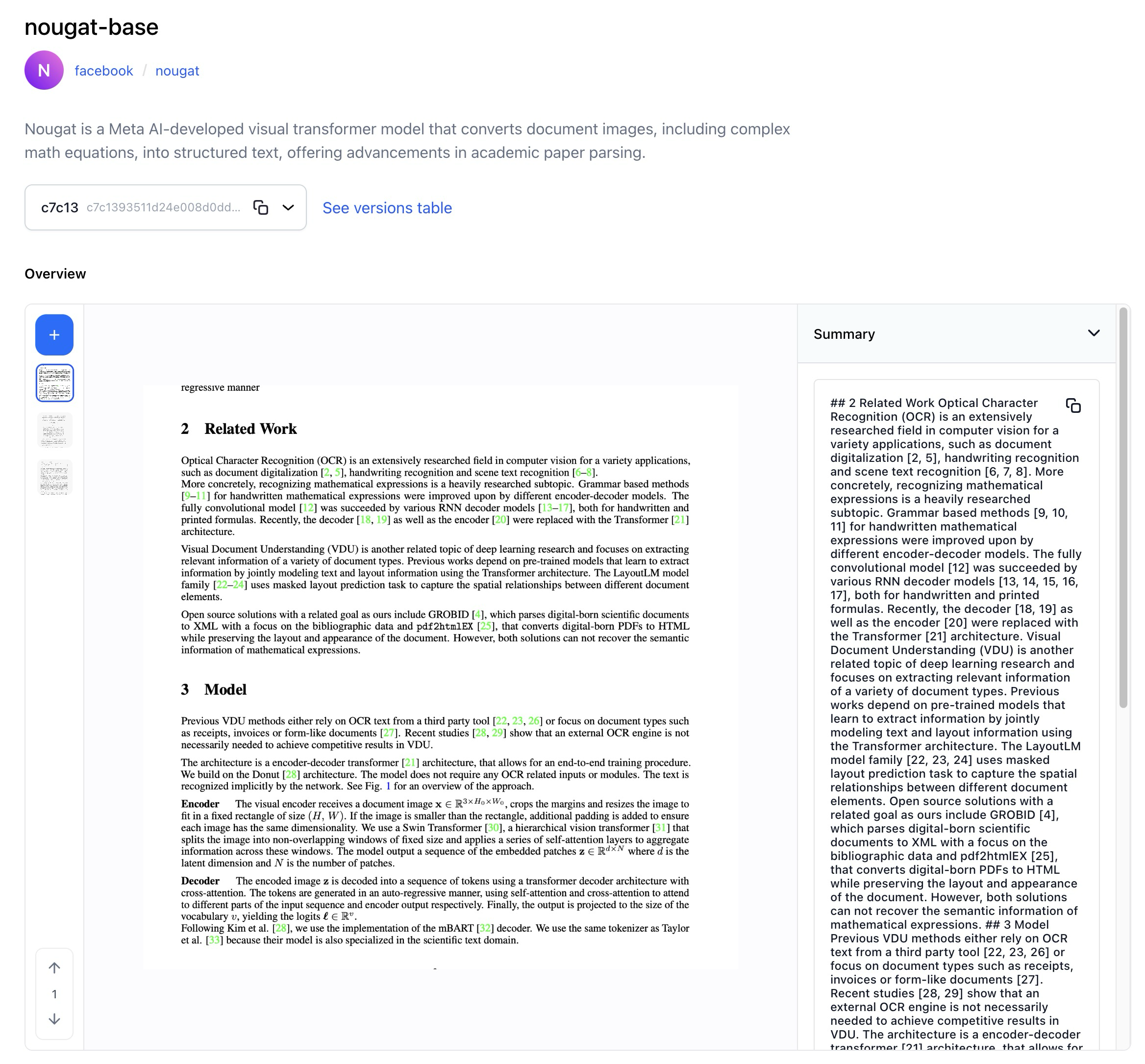
- Wrapped Nougat-base, a Meta AI-developed visual transformer model that converts document images, including complex math equations, into structured text, offering advancements in academic paper parsing.
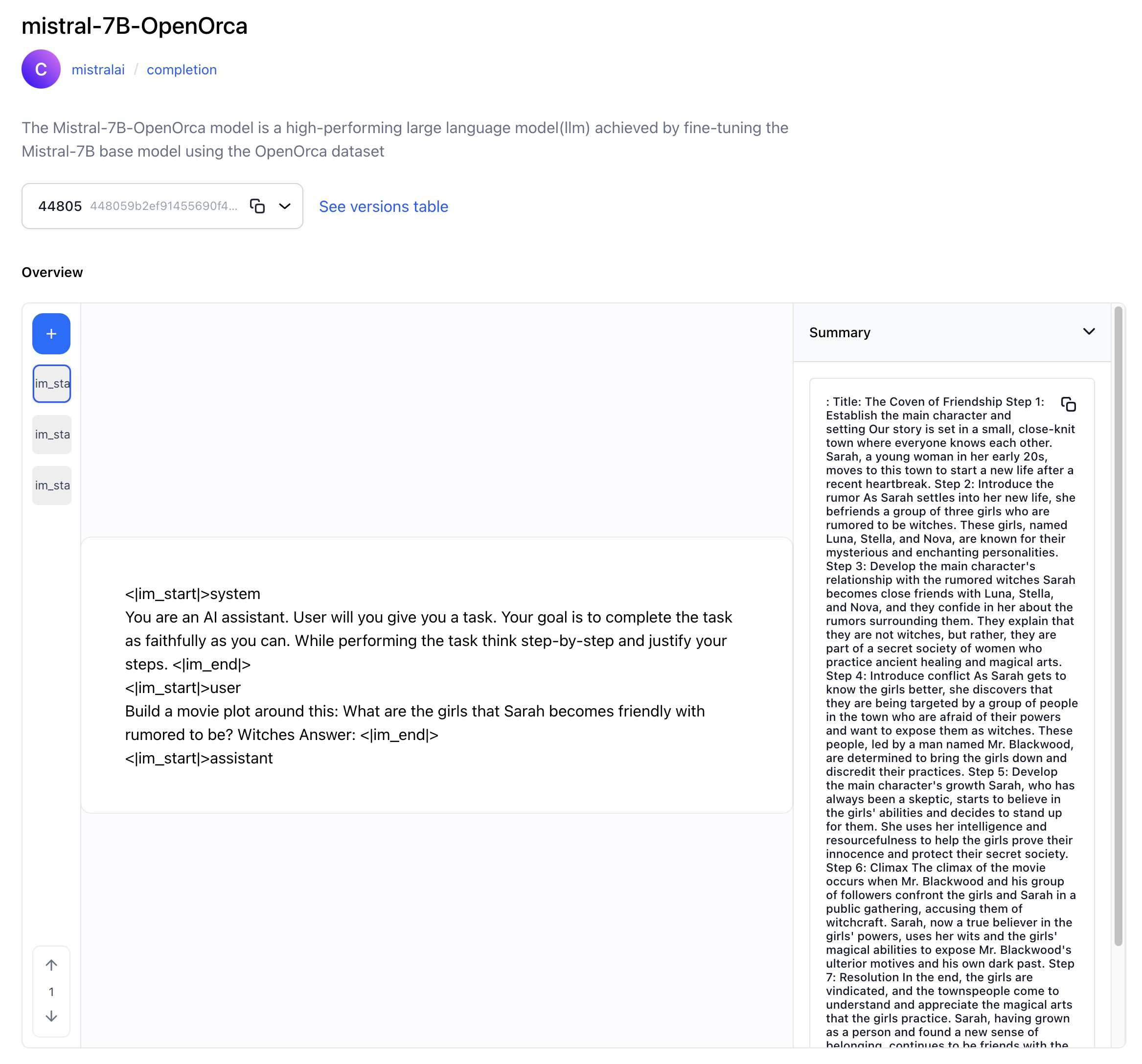
- Wrapped Mistral-7B-OpenOrca, a high-performing large language model achieved by fine-tuning the Mistral-7B base model using the OpenOrca dataset.
- Wrapped Zephyr-7B-alpha, a 7 billion parameter model, fine-tuned on Mistral-7b and outperformed the Llama2-70B-Chat on MT Bench.
- Wrapped OpenHermes-2-mistral-7B, a 7 billion LLM fine-tuned on Mistral with 900,000 entries of primarily GPT-4 generated data from open datasets.
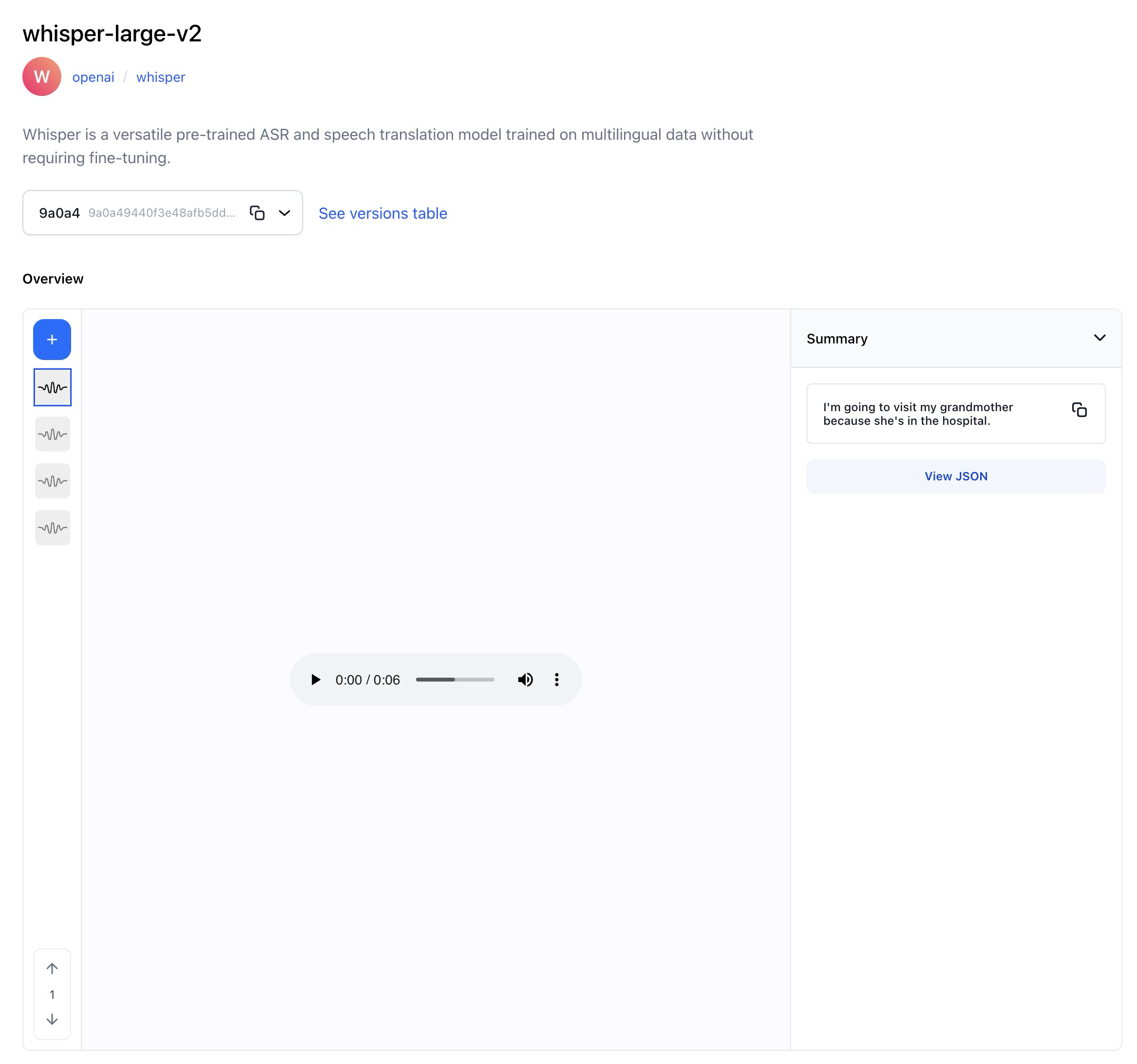
- Wrapped Whisper-large-v2, a versatile pre-trained ASR and speech translation model trained on multilingual data without requiring fine-tuning.
- Wrapped SSD-1B, a diffusion-based text-to-image model—it's 50% smaller and 60% faster than SDXL 1.0.
- Wrapped Jina-embeddings-v2, an English text embedding model by Jina AI. It’s based on the Bert architecture with an 8192-sequence length, outperforming OpenAI's embedding model in various metrics.
Models
Improved min_value range for consistency across all model types
- For embedding-classifiers, we’ve standardized min_value to have a range of 0 to 1 with a step size of .01. For most of the other model types, we’ve standardized it to have a range of 0 to 100 with a step size of .1.
Made time information changes to the Centroid Tracker model
- We’ve made significant improvements to the Centroid Tracker, specifically within the "time_info" section. We added "start_time" and "end_time" to provide precise information regarding when an object was detected and when detection ceased.
Made improvements to the Model-Viewer’s version table
- We made the changes to make the table more consistent with the evaluation leaderboard. It now provides users with a cohesive and familiar interface.
- We relocated evaluation actions from a separate module to the table to enhance the user experience.
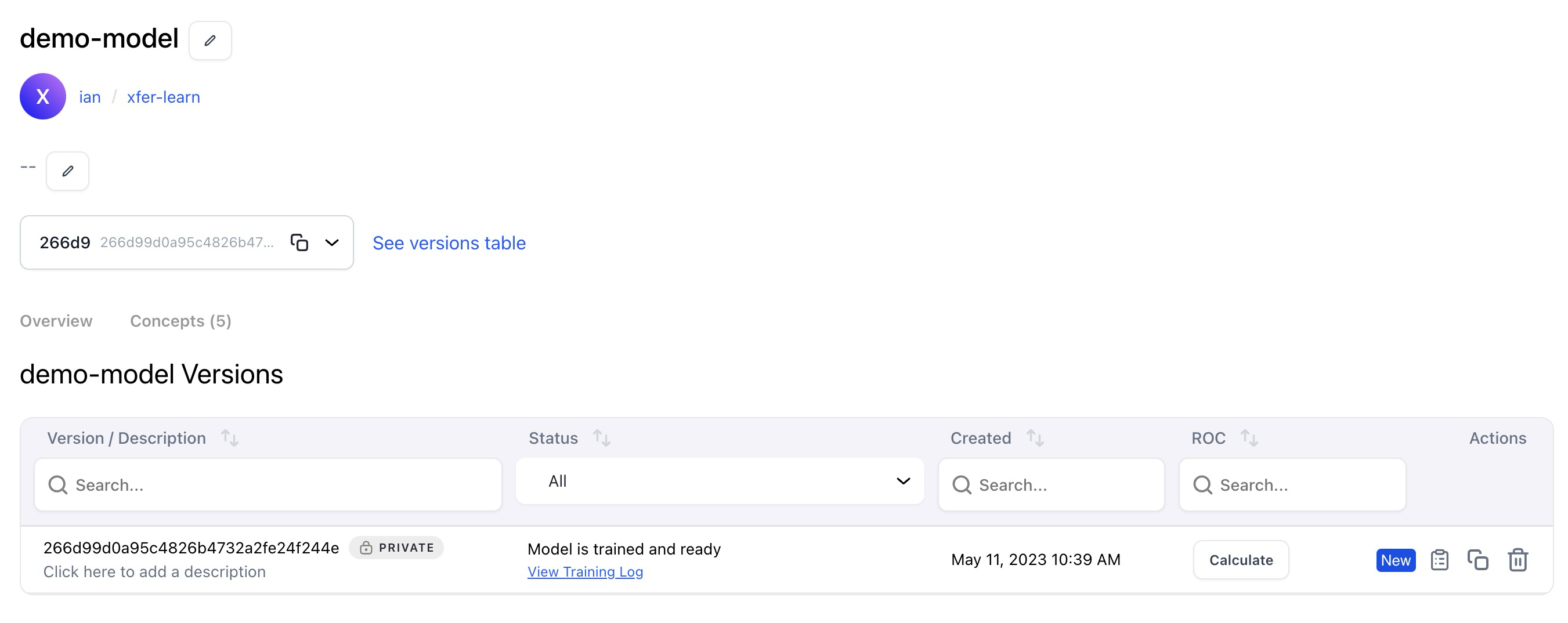
Made significant improvements to enhance the dataset and concept selection process when training models
- Model builders who haven't yet created datasets or dataset versions can now conveniently choose the 'app default dataset' in the model training editor screen. This option provides visibility into the labeled input counts, allowing users to verify their data before initiating the training process.
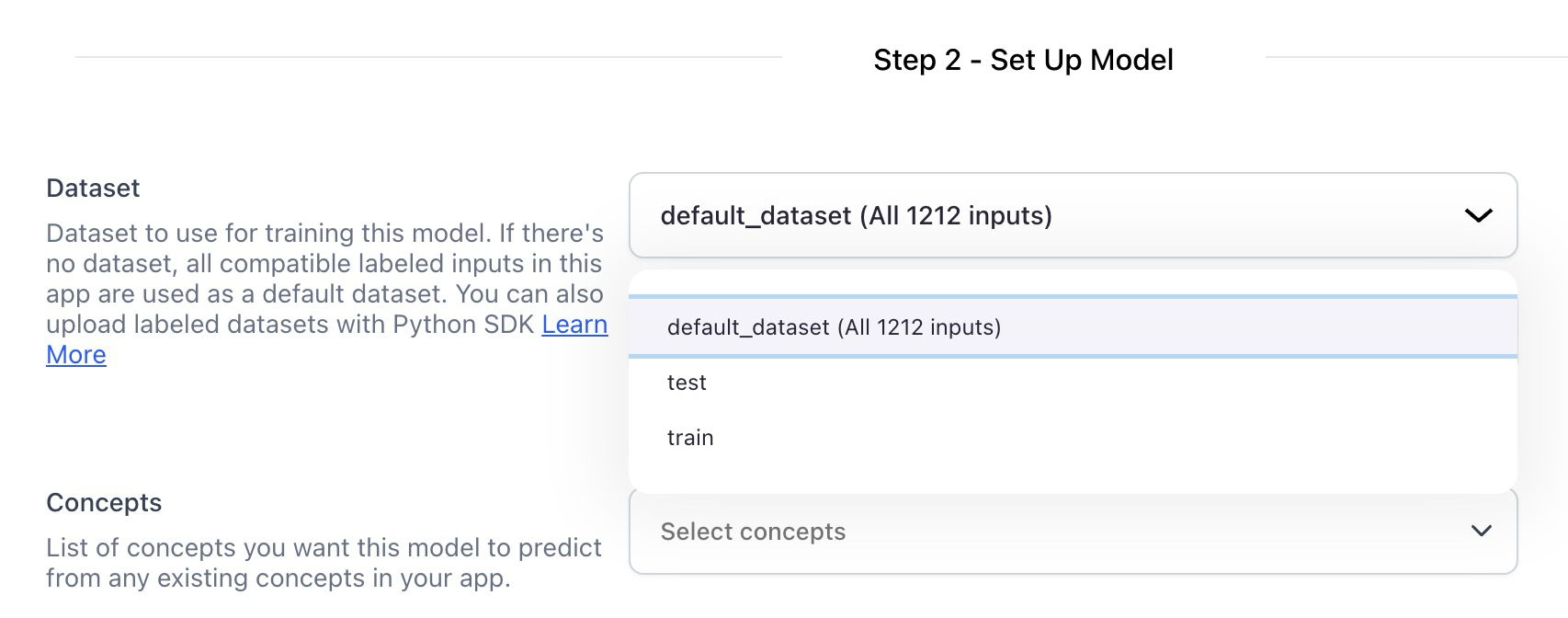
- The concept selection interface now displays the labeled input count for each concept. This feature helps users prevent training concepts without adequate labeled inputs and simplifies the process of identifying data imbalances, all without the need to navigate away from the screen.
Listing Resources
Added ability to view whether a resource is available publicly or privately
- When listing your own resources, such as models, we've added an icon that clearly indicates whether they are private or shared within the Community.
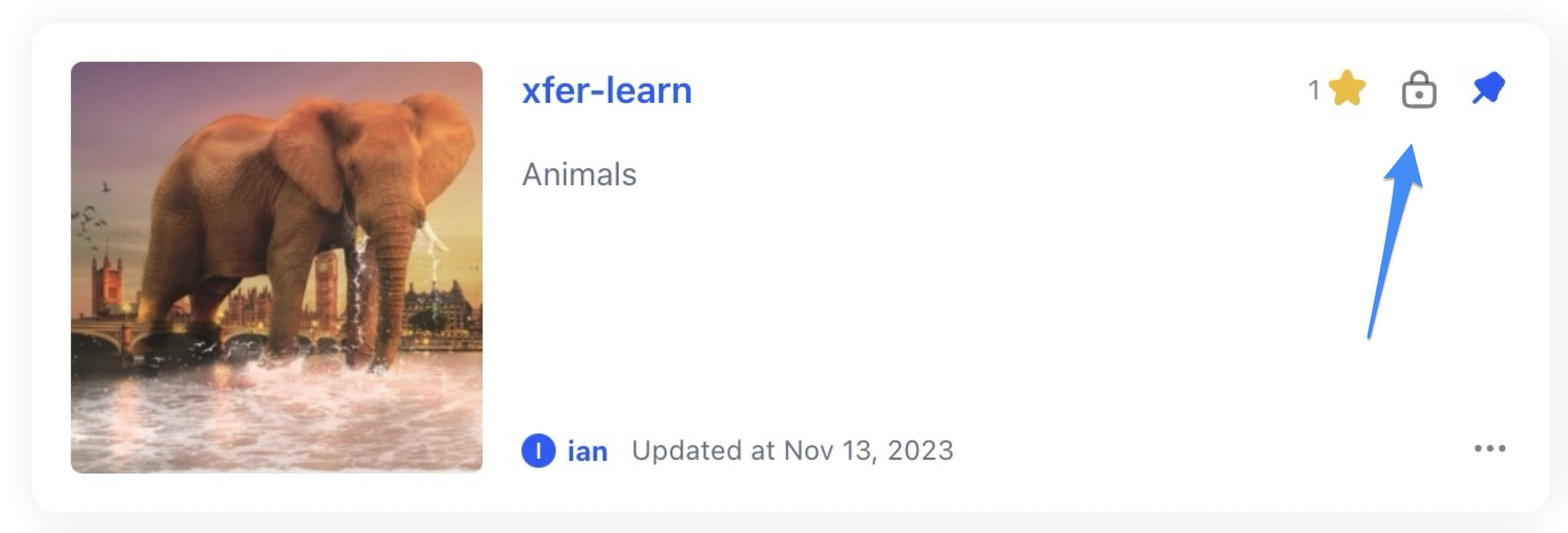
Added starring option to modules
- Similar to other resources, you can now mark modules as favorites by using the star icon.
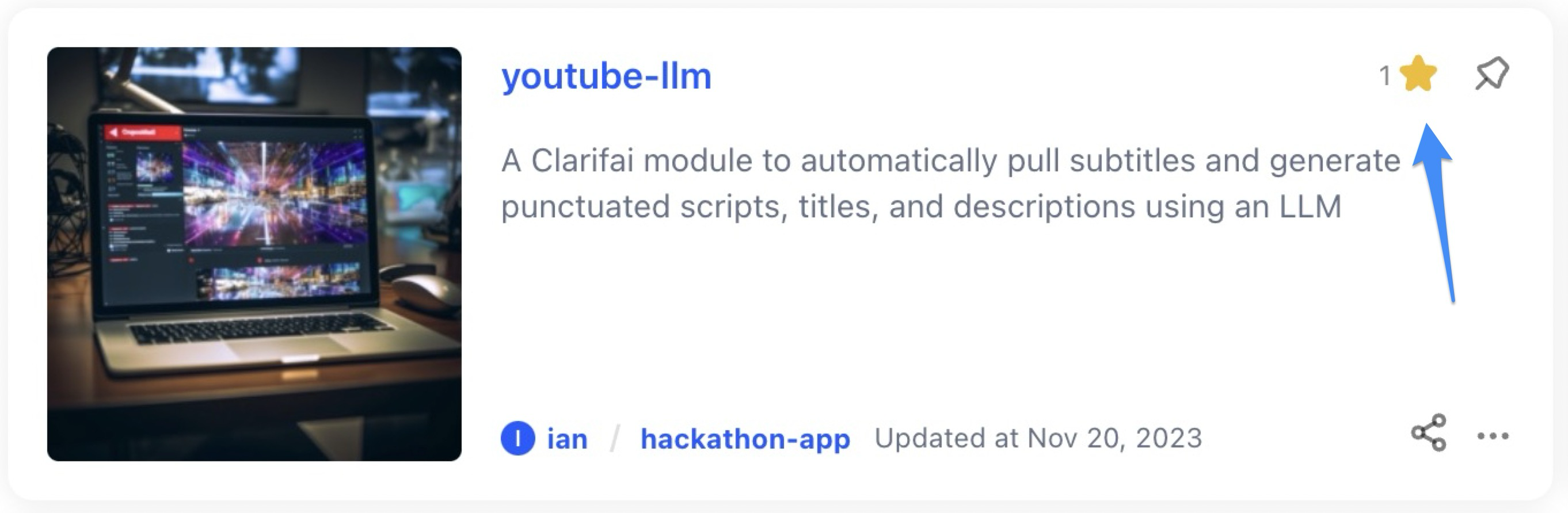
Improved the accessibility of starred resources
- Previously, you could only access starred resources by navigating to the top-right profile menu and selecting the “starred” option. You can now easily access both your own and Community resources by choosing either the “All” or “Starred” view on the main screen for listing resources, making it more intuitive to find what you need.

License Types
Added several new license types
- If you want to select a license type for your resource, we've expanded your options to provide a diverse range that can cater to your unique preferences.
Organization Settings and Management
Enhanced searching for organization members
- You can now search for organization members using both their first name and last name, individually or in combination.
Adjusted a team's app view of organization apps
- We removed 'App name,' added a non-sortable 'App description' with a maximum of two lines, introduced 'Date created,' and optionally included 'Last updated' if the information is available via the API.
Search
Made searchability enhancements on the Community platform
- You can now enjoy an upgraded experience when searching by resource ID, user ID, short description, and even markdown notes. These enhancements ensure that you can find the exact information you need more efficiently and accurately.
Input-Manager
Implemented caching of input thumbnails throughout Input-Manager and Input-Viewer
- This caching mechanism significantly enhances the overall efficiency of our system by minimizing the need to repeatedly load or generate thumbnails, resulting in faster response times and smoother interactions for our users.
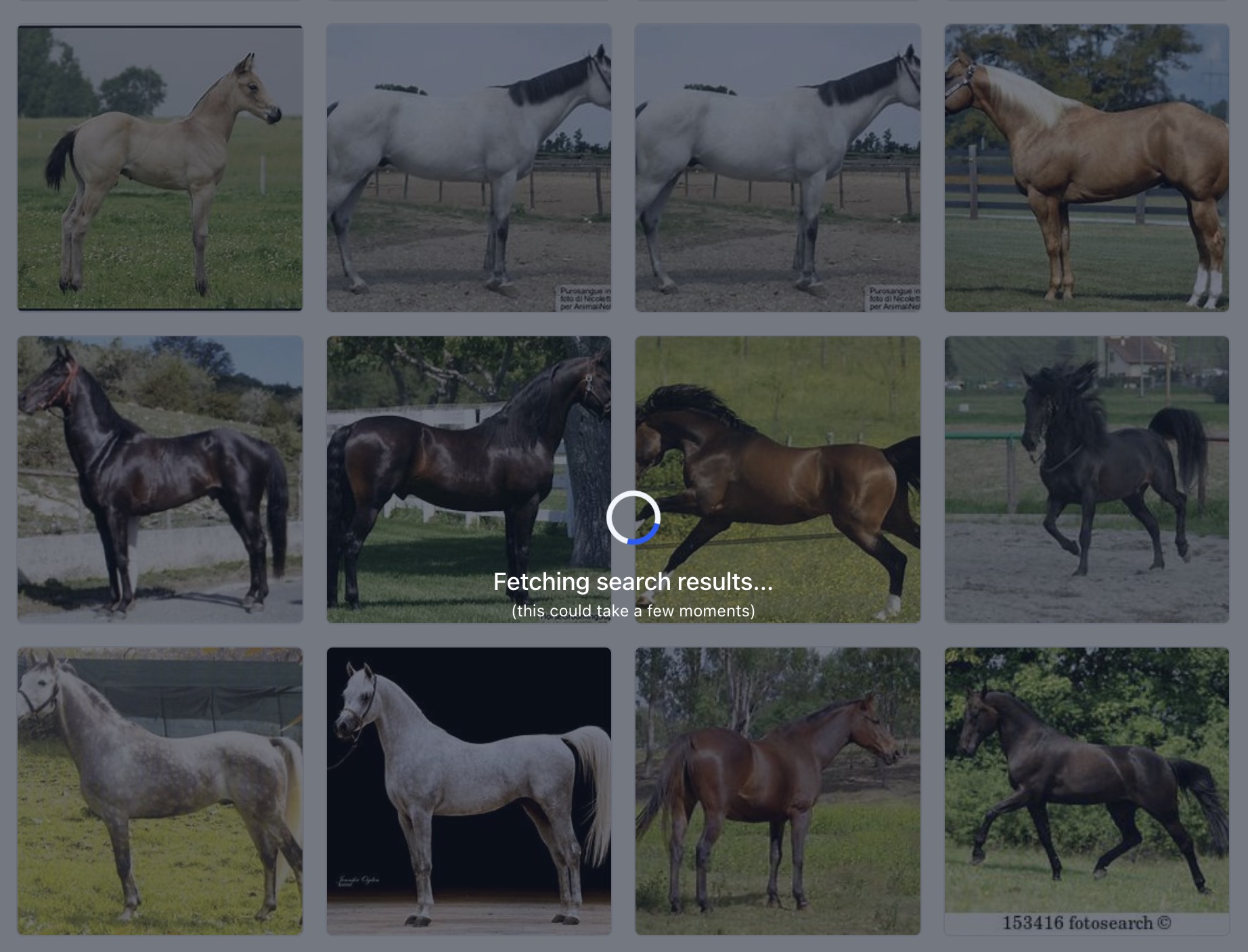
Enhanced user experience during smart searches
- Instead of blocking user actions, we now display a non-intrusive loading overlay. This overlay will be visible during search requests within the Input-Manager, ensuring that the search grid results remain accessible without disruption.
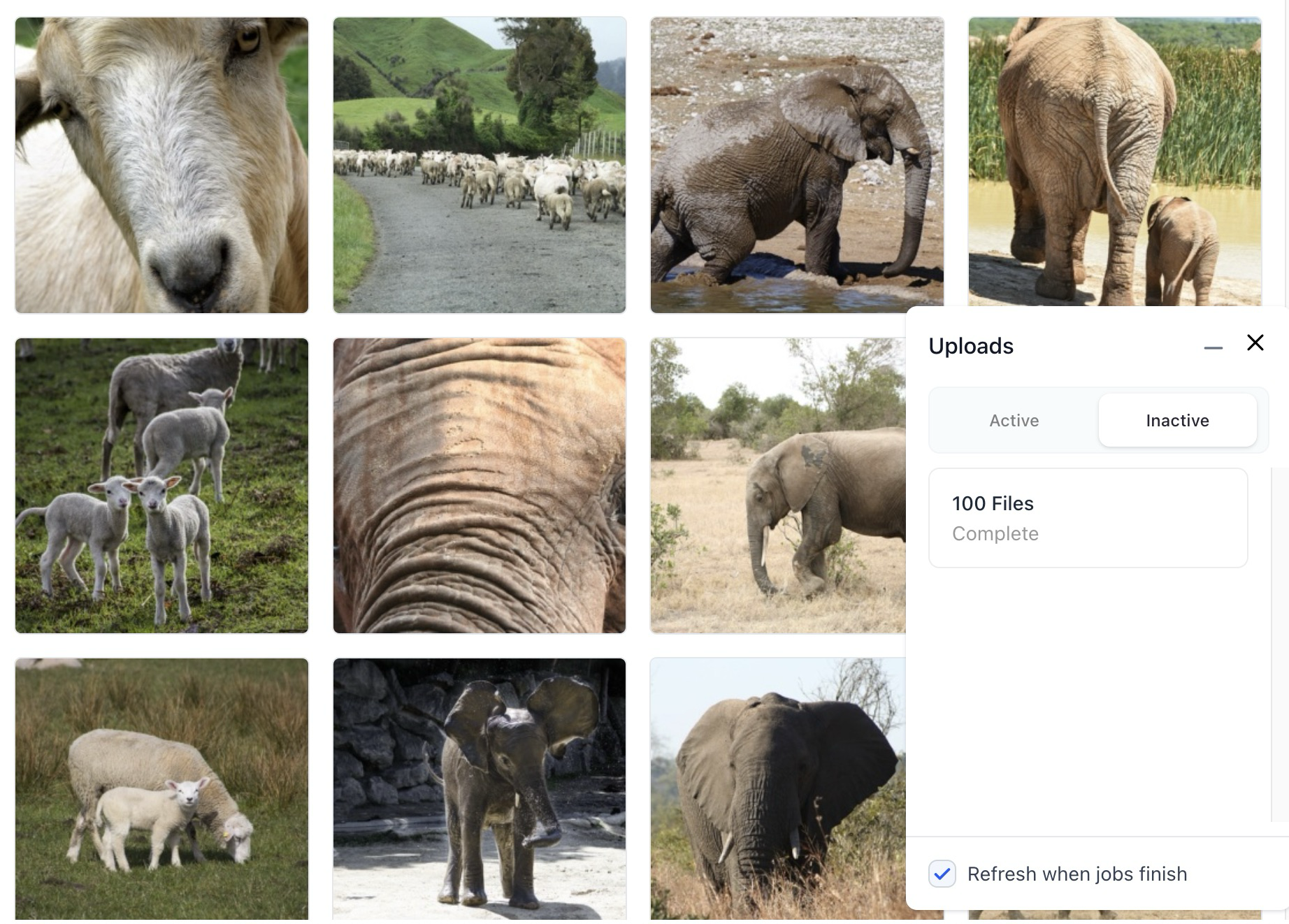
Improved the behavior of the input upload job monitor in the Input-Manager
- If you upload inputs on the Input-Manager, a small sidebar window appears at the bottom-right corner of the screen, providing you with real-time status updates on the upload process. There is also a checkbox in the pop-up window, allowing you to tailor your monitoring preferences to better suit your needs.
- If the checkbox is checked, the upload monitor will initiate polling. It will also immediately update the input list as new inputs become available.
- If the checkbox is unchecked, polling will continue. However, the input list will only be updated once ALL jobs have been completed. Previously, there was an issue where unchecking the checkbox would halt polling, preventing updates.
Prevented manual page refresh during input uploads
- We now prevent users from refreshing the page while inputs are still uploading. We display a modal that prompts the user to confirm whether they want to reload the page or not. This ensures users are aware of ongoing uploads and helps avoid unintended disruptions caused by manual page refreshes.
Onboarding Flow
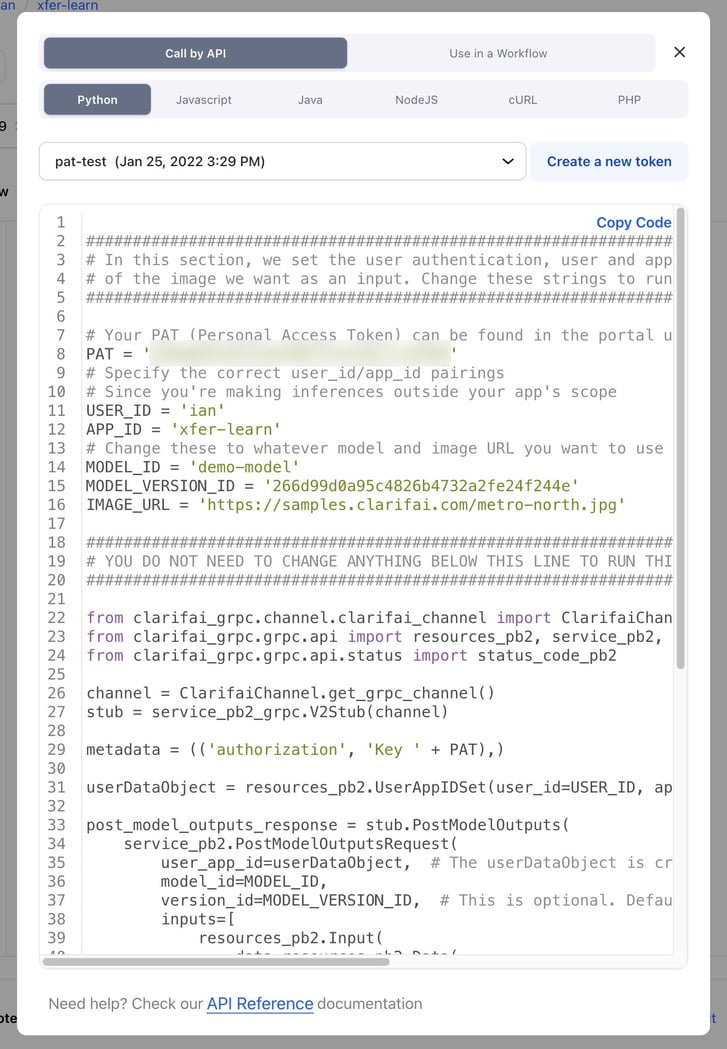
Reordered the 'Use Model' and 'Use Workflow' tabs in the onboarding flow
- In the 'Use Model' or 'Use Workflow' pop-up, we moved 'Call by API' to the top position and made 'Python' the first choice.
- We applied the changes within the 'Use Model' pop-up, 'Use Workflow' pop-up, and in the onboarding version of 'Use Model.'