Welcome to Brand_new_ian Overview page
Clarifai app is a place for you to organize all of the content including models, workflows, inputs and more.
For app owners, API keys and Collaborators have been moved under App Settings.
0
Datasets
Datasets
0
1
Models
Models
1
0
Workflows
Workflows
0
0
Modules
Modules
0
YOLOv6t-coco
Introduction
YOLOv6 is a single-stage object detection framework dedicated to industrial applications, with hardware-friendly efficient design and high performance.
YOLO has quickly established itself as one of the most important computer vision models. This is due to its approach of multi-size bounding boxes and the fact that it only needs to run once through the model pipeline, resulting in high efficiency and precision.
The original YOLO model was created by Joseph Redmon in 2016. Since then, numerous various iterations of YOLO have been release by multiple people, each with different variations based on the size of the images the model was trained on, as well as the number of parameters in the architecture. Each model excels at a different task, some being more efficient at the expense of accuracy.
More Info
- Original Repository: GitHub
- HuggingFace: nateraw/yolov6t

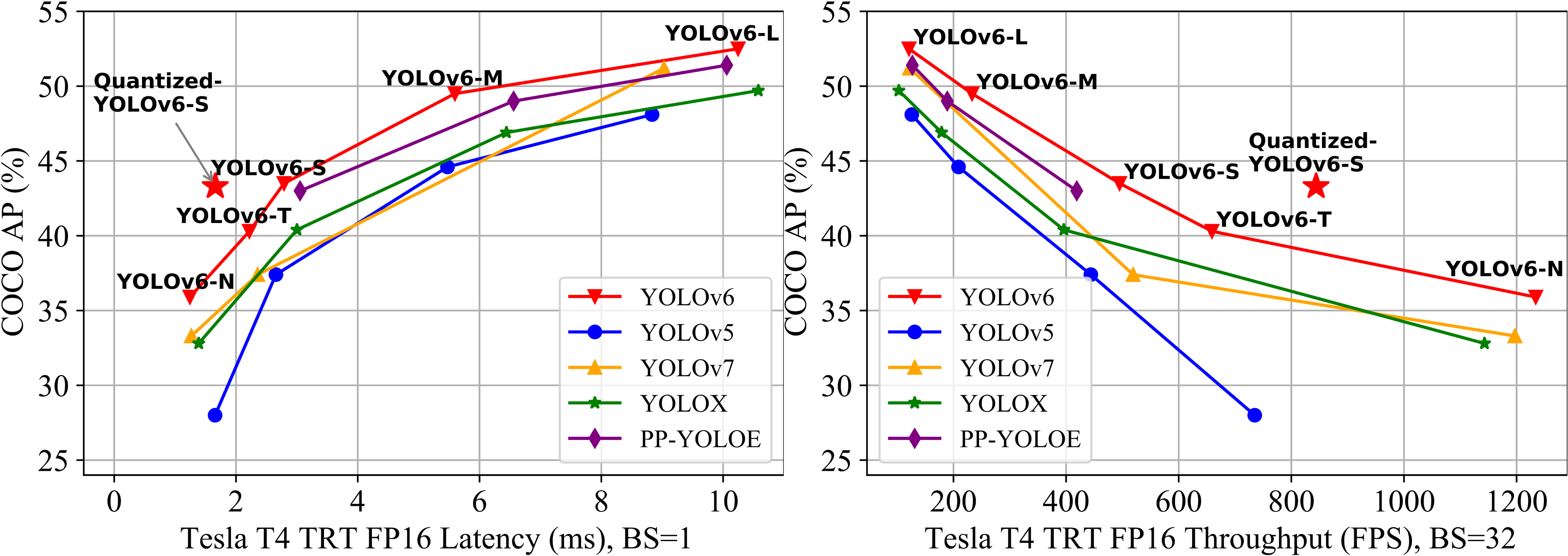
Comparison of state-of-the-art efficient object detectors.
YOLOv6 Paper
YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
Authors: Chuyi Li, Lulu Li, Hongliang Jiang, Kaiheng Weng, Yifei Geng, Liang Li, Zaidan Ke, Qingyuan Li, Meng Cheng, Weiqiang Nie, Yiduo Li, Bo Zhang, Yufei Liang, Linyuan Zhou, Xiaoming Xu, Xiangxiang Chu, Xiaoming Wei, Xiaolin Wei
Abstract
For years, the YOLO series has been the de facto industry-level standard for efficient object detection. The YOLO community has prospered overwhelmingly to enrich its use in a multitude of hardware platforms and abundant scenarios. In this technical report, we strive to push its limits to the next level, stepping forward with an unwavering mindset for industry application. Considering the diverse requirements for speed and accuracy in the real environment, we extensively examine the up-to-date object detection advancements either from industry or academia. Specifically, we heavily assimilate ideas from recent network design, training strategies, testing techniques, quantization, and optimization methods. On top of this, we integrate our thoughts and practice to build a suite of deployment-ready networks at various scales to accommodate diversified use cases. With the generous permission of YOLO authors, we name it YOLOv6. We also express our warm welcome to users and contributors for further enhancement. For a glimpse of performance, our YOLOv6-N hits 35.9% AP on the COCO dataset at a throughput of 1234 FPS on an NVIDIA Tesla T4 GPU. YOLOv6-S strikes 43.5% AP at 495 FPS, outperforming other mainstream detectors at the same scale~(YOLOv5-S, YOLOX-S, and PPYOLOE-S). Our quantized version of YOLOv6-S even brings a new state-of-the-art 43.3% AP at 869 FPS. Furthermore, YOLOv6-M/L also achieves better accuracy performance (i.e., 49.5%/52.3%) than other detectors with a similar inference speed. We carefully conducted experiments to validate the effectiveness of each component. Our code is made available at this https URL.
YOLO Original Paper
You Only Look Once: Unified, Real-Time Object Detection
Authors: Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
Abstract
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities. A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation. Since the whole detection pipeline is a single network, it can be optimized end-to-end directly on detection performance. Our unified architecture is extremely fast. Our base YOLO model processes images in real-time at 45 frames per second. A smaller version of the network, Fast YOLO, processes an astounding 155 frames per second while still achieving double the mAP of other real-time detectors. Compared to state-of-the-art detection systems, YOLO makes more localization errors but is less likely to predict false positives on background. Finally, YOLO learns very general representations of objects. It outperforms other detection methods, including DPM and R-CNN, when generalizing from natural images to other domains like artwork.
Dataset
YOLOv6 was trained on the MS COCO (Microsoft Common Objects in Context) 2017 training set, and the accuracy is evaluated on the COCO 2017 validation set.
COCO is a dataset is a large-scale object detection, segmentation, key-point detection, and captioning dataset. The dataset consists of 328K images. It has around 1.5 million object instances, 80 object categories, 91 stuff categories, 5 captions per image, and 250.000 person instances labeled with keypoints (17 possible keypoints, such as left eye, nose, right hip, right ankle, etc.). Captioning uses natural language descriptions of the images based on the paired MS COCO Captions dataset.
More Info
COCO Paper
Microsoft COCO: Common Objects in Context
Authors: Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, Piotr Dollár
Abstract
We present a new dataset with the goal of advancing the state-of-the-art in object recognition by placing the question of object recognition in the context of the broader question of scene understanding. This is achieved by gathering images of complex everyday scenes containing common objects in their natural context. Objects are labeled using per-instance segmentations to aid in precise object localization. Our dataset contains photos of 91 objects types that would be easily recognizable by a 4 year old. With a total of 2.5 million labeled instances in 328k images, the creation of our dataset drew upon extensive crowd worker involvement via novel user interfaces for category detection, instance spotting and instance segmentation. We present a detailed statistical analysis of the dataset in comparison to PASCAL, ImageNet, and SUN. Finally, we provide baseline performance analysis for bounding box and segmentation detection results using a Deformable Parts Model.
COCO Captions Paper
Microsoft COCO Captions: Data Collection and Evaluation Server
Authors: Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, C. Lawrence Zitnick
Abstract
In this paper we describe the Microsoft COCO Caption dataset and evaluation server. When completed, the dataset will contain over one and a half million captions describing over 330,000 images. For the training and validation images, five independent human generated captions will be provided. To ensure consistency in evaluation of automatic caption generation algorithms, an evaluation server is used. The evaluation server receives candidate captions and scores them using several popular metrics, including BLEU, METEOR, ROUGE and CIDEr. Instructions for using the evaluation server are provided.
Performance and Benchmarks
| Model | Size | mAPval 0.5:0.95 | SpeedT4 trt fp16 b1 (fps) | SpeedT4 trt fp16 b32 (fps) | Params (M) | FLOPs (G) |
|---|---|---|---|---|---|---|
| YOLOv6-N | 640 | 35.9300e 36.3400e | 802 | 1234 | 4.3 | 11.1 |
| YOLOv6-T | 640 | 40.3300e 41.1400e | 449 | 659 | 15.0 | 36.7 |
| YOLOv6-S | 640 | 43.5300e 43.8400e | 358 | 495 | 17.2 | 44.2 |
| YOLOv6-M | 640 | 49.5 | 179 | 233 | 34.3 | 82.2 |
| YOLOv6-L-ReLU | 640 | 51.7 | 113 | 149 | 58.5 | 144.0 |
| YOLOv6-L | 640 | 52.5 | 98 | 121 | 58.5 | 144.0 |
Comparisons with other YOLO-series detectors on COCO 2017 val:
| Method | Input Size | APval | APval50 | FPS (bs=l) | FPS (bs=32) | Latency (bs=1) | Params | FLOPS |
|---|---|---|---|---|---|---|---|---|
| Y0L0v5-N [10] | 640 | 28.0% | 45.7% | 602 | 735 | 1.7 ms | 1.9 M | 4.5 G |
| YOLOv5-S [10] | 640 | 37.4% | 56.8% | 376 | 444 | 2.7 ms | 7.2 M | 16.5 G |
| YOLOv5-M [10] | 640 | 45.4% | 64.1% | 182 | 209 | 5.5 ms | 21.2M | 49.0 G |
| YOLOv5-L [10] | 640 | 49.0% | 67.3% | 113 | 126 | 8.8 ms | 46.5 M | 109.1 G |
| YOLOX-Tiny [7] | 416 | 32.8% | 50.3%* | 717 | 1143 | 1.4 ms | 5.1 M | 6.5 G |
| YOLOX-S [7] | 640 | 40.5% | 59.3%* | 333 | 396 | 3.0 ms | 9.0 M | 26.8 G |
| YOLOX-M [7] | 640 | 46.9% | 65.6%* | 155 | 179 | 6.4 ms | 25.3 M | 73.8 G |
| YOLOX-L [7] | 640 | 49.7% | 68.0%* | 94 | 103 | 10.6 ms | 54.2 M | 155.6 G |
| PPYOLOE-S [45] | 640 | 43.1% | 59.6% | 327 | 419 | 3.1 ms | 7.9 M | 17.4 G |
| PPYOLOE-M [45] | 640 | 49.0% | 65.9% | 152 | 189 | 6.6 ms | 23.4 M | 49.9 G |
| PPYOLOE-L [45] | 640 | 51.4% | 68.6% | 101 | 127 | 10.1 ms | 52.2 M | 110.1 G |
| YOLOv7-Tiny [42] | 416 | 33.3%* | 49.9%* | 787 | 1196 | 1.3 ms | 6.2 M | 5.8 G |
| YOLOv7-Tiny [42] | 640 | 37.4%* | 55.2%* | 424 | 519 | 2.4 ms | 6.2 M | 13.7 G* |
| YOLOv7 [42] | 640 | 51.2% | 69.7% | 110 | 122 | 9.0 ms | 36.9 M | 104.7 G |
| YOLOv6-N | 640 | 35.9% | 51.2% | 802 | 1234 | 1.2 ms | 4.3 M | 11.1 G |
| YOLOv6-T | 640 | 40.3% | 56.6% | 449 | 659 | 2.2 ms | 15.0 M | 36.7 G |
| YOLOv6-S | 640 | 43.5% | 60.4% | 358 | 495 | 2.8 ms | 17.2 M | 44.2 G |
| YOLOv6-Mi | 640 | 49.5% | 66.8% | 179 | 233 | 5.6 ms | 34.3 M | 82.2 G |
| YOLOv6-L-ReLU* | 640 | 51.7% | 69.2% | 113 | 149 | 8.8 ms | 58.5 M | 144.0 G |
| YOLOv6-Li | 640 | 52.5% | 70.0% | 98 | 121 | 10.2 ms | 58.5 M | 144.0 G |
- DescriptionThis is my first brand new community app
- Base Workflow
- Last UpdatedMar 10, 2023
- Default Languageen
- Share
- Visual Detector